
OCRKit Online Help – The Missing Manual
Getting started

To recognize the text of an PDF or image file simply drag and drop it onto the OCRKit application icon or use the File menu: Open...
The preference settings are sorted into four main categories that you can reach from the top menu bar:
OCR
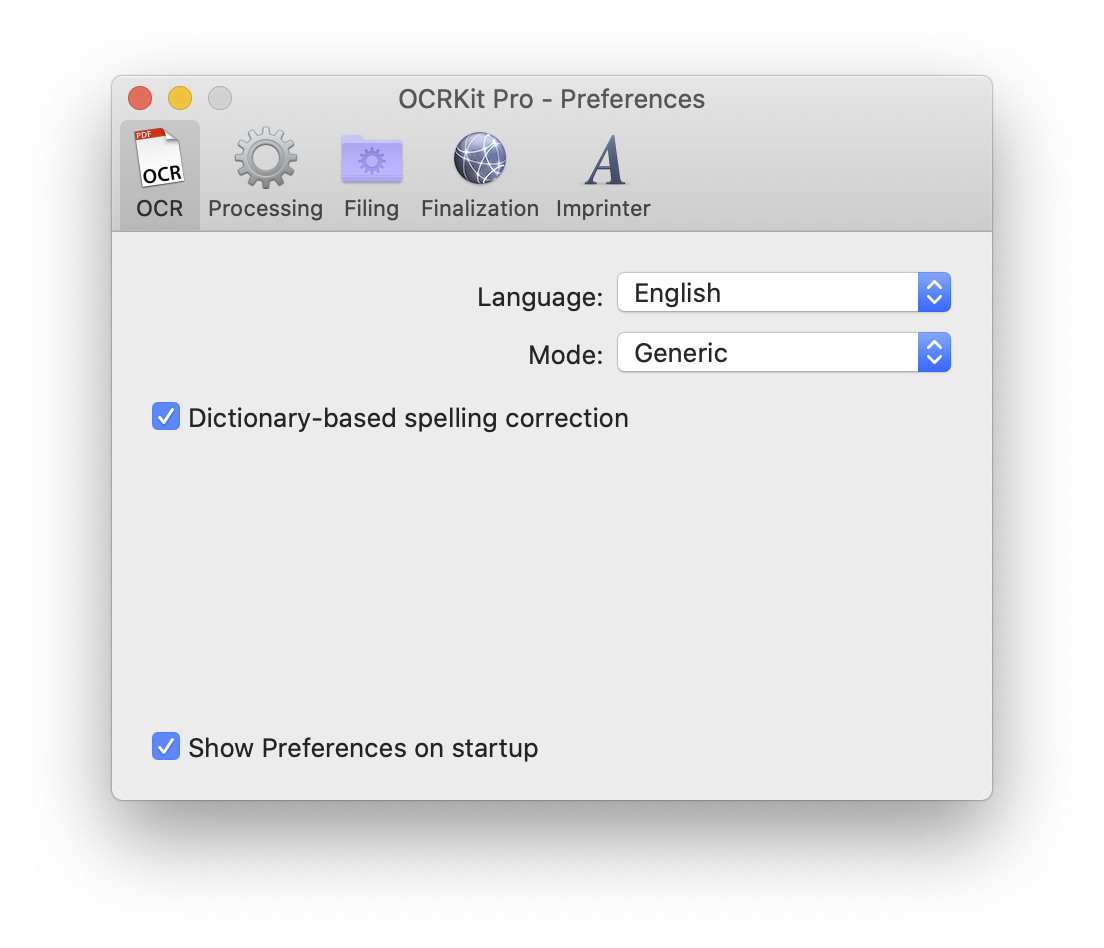
Here you choose the language to be used for the optical character recognition.
The mode option allows to choose special processing options for fax and dot-matrix printed documents.
For regular office text the dictionary based spelling correction is usually helpful to improve results. For other alpha numeric data, such as scientific data or financial numbers turning off this option can be an advantage.
Processing
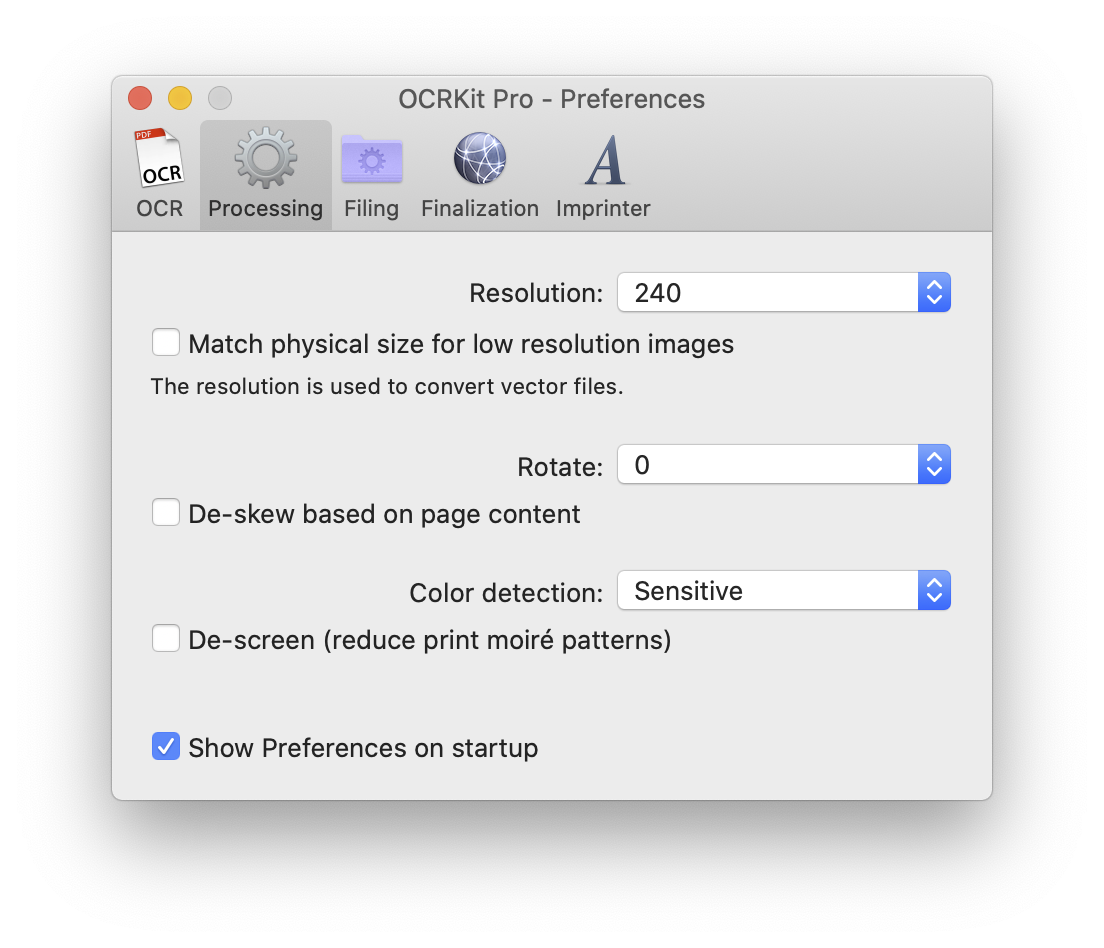
OCRKit tries to re-use images from source files 1:1. However PDF pages may contain more than one image, or vector and text elements. In this case the resolution option controls the resolution used to rasterize the whole pages to one image. Using the match physical size for low resolution images, OCRKit can try to detect the actual page size for photos without resolution information, such as taken with a mobile phone.
The rotate option allows you to adjust the page orientation before processing - for example when the creation application rotated landscape pages. De-skew based on page content allows to correct small skew angle often produced by scanning paper in a scanner.
The color detection can be used to automatically convert color images to gray or black and white to save storage space.
Using the de-screen option you can reduce the pattern of small dots a times visible when scanning offset printed magazines or newspapers. It can also be useful to remove other small dot noise on your source material.
Filing
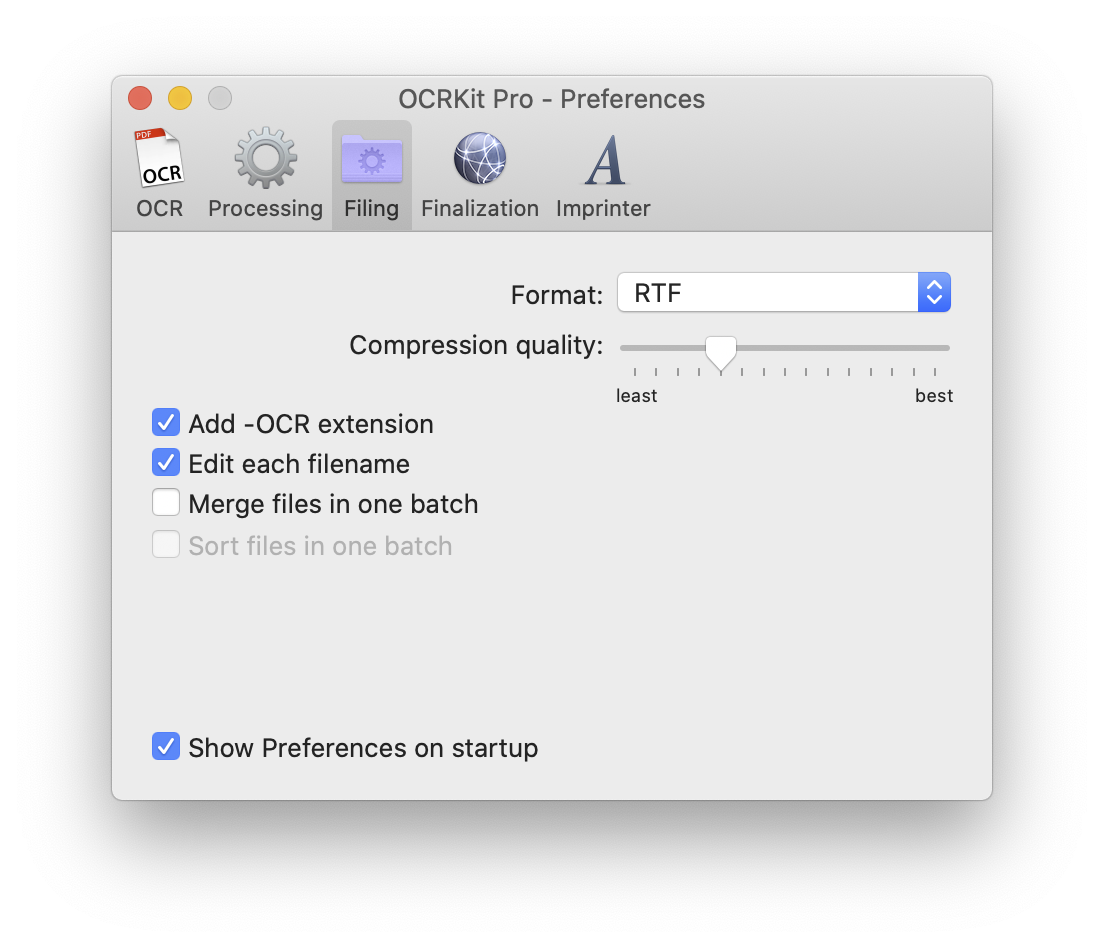
With the Format option you select the output format. This can be Searchable or Highly Compressed PDF, or pure text formats, such as Rich-Text or HTML.
The compression quality controls the resulting file size, and thus affect the images quality. By moving this option further to the left side you receive smaller files by compromising image quality by compression artifacts.
By default OCRKit uses the original filename, while you can choose to add an -OCR extension or edit each filename manually.
When you select or drop multiple files in OCRKit for processing, they are processed one by one. You can also select to merge all those files in one batch into a single output file. E.g. for converting a bunch of JPEG or TIFF files into one highly compressed and searchable PDF.
OCRKit is using the order as received by the operating system. While this usually is the order you selected the files in the multi-selection, at times macOS's Finder unfortunately sorts them in an arbitrary order. In any case you can choose to have OCRKit sort the files to retain a reliably order while merging all files in one batch.
Finalization
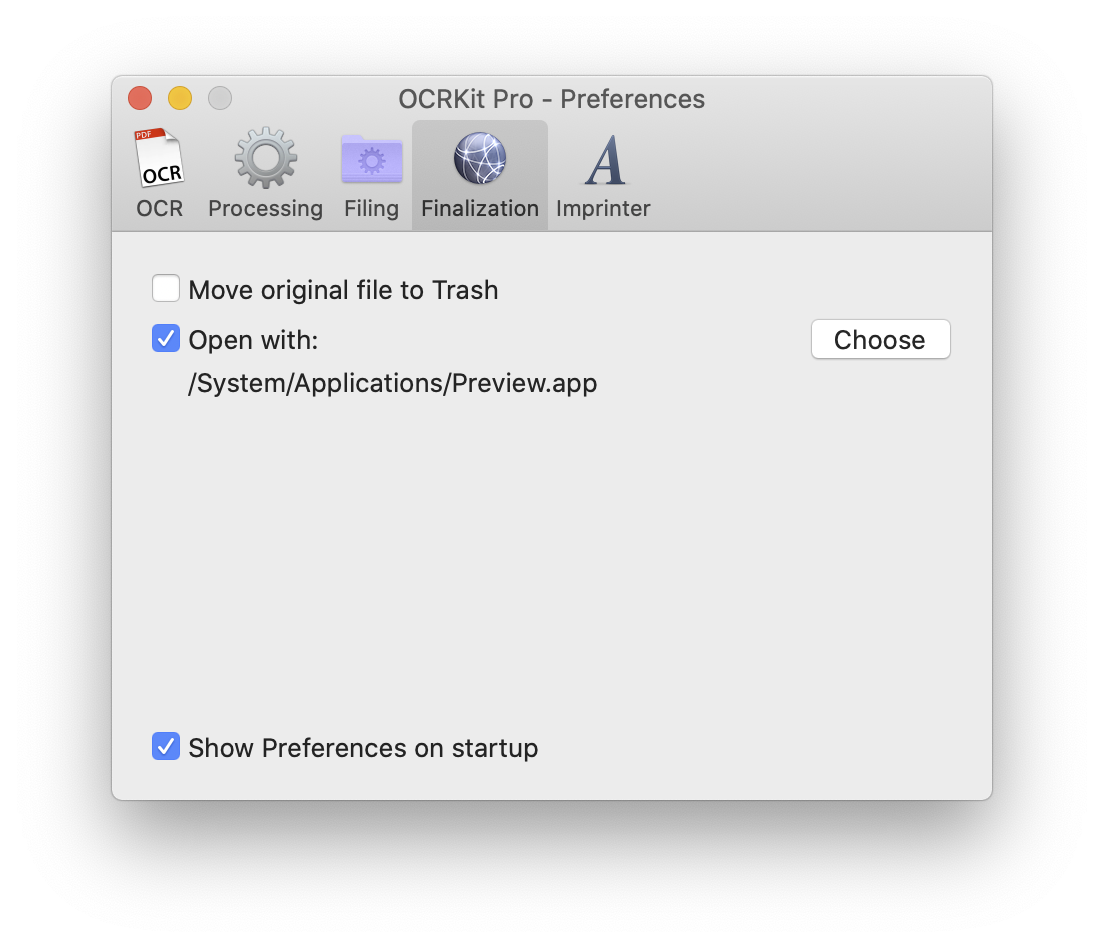
In the Finalization tab you can choose whether to remove the original document to the system trash after processing, and whether to notify another application about the new file. This can be used with Apple's Preview for visual control, or database and cloud application to archive the final document.
Imprinter
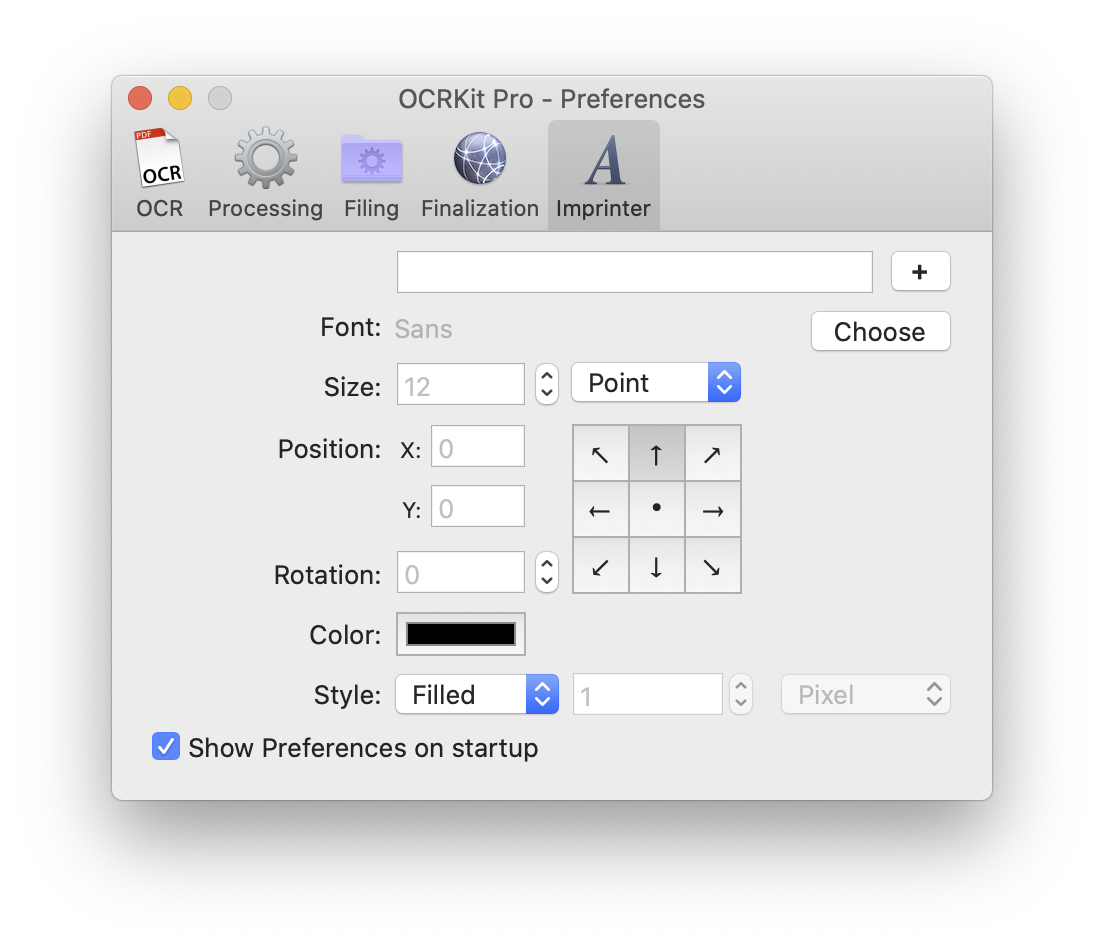
With the digital imprinter of the Pro version you can add watermarks to your documents. Commonly used marks are CONFIDENTIAL, PRELIMINARY, COPY, or similar terms that suit your workflow, in any font, shape, or rotation.

You control the language used for the text recognition, as well as all other processing settings such as the output format (PDF, RTF, HTML or plain/text) in the OCRKit Preferences... menu.
My image does not OCR well
This is usually the result of poor image quality. If your image is barely readable for a human, you can imagine it is even harder to identify the text for a computer program. The resolution for scans of regular office paperwork should be between 200 and 300 dpi (dots / pixel per inch). We recommend using 300 dpi for all regular daily office material. Using more than 300 dpi does not necessarily improve results, but mainly increases the resulting PDF files. Unless you use Automatic rotation of the Pro version the text must also be in the right, readable orientation.
AppleScript
You can also script OCRKit to integrate it into your specific workflow. For example process incoming files, via shared folder, from MFP copy machine, etc. and simply tell OCRKit to open and thus process is via AppleScript:
tell application "OCRKit" set resolution to 240 set rotation to 180 set destination app to "/Application/Some.app" -- the legacy of AppleScript POSIX path handling, ... open "Users:admin:Desktop:orderform.pdf" open POSIX path of "/Users/Admin/Desktop/orderform.pdf" end tell
Command line
Since OCRKit version 2.5 direct command line scripting is supported. This greatly simplifies the use of OCRKit in batch processing, allows to set more options and is also more robust and cross-platform than AppleSCript.
OCRKit.app/Contents/MacOS/OCRKit \
--lang en | de | fr | es | ... \
--format pdf | html | rtf | text \
--no-progress \
--output out-file in-file
Since OCRKit version 16.9 additional command line options are supported:
-r, --recursive directory
Scan directory recursively for new files. Skips files from OCRKit, with text layer or vector graphics.
--pattern "regex"
Pattern used to match filenames during recursive scans. Defaults to "%.pdf$",
recommendation for TIFF is "%.tiff?$"
--log file
Write log file information and statistics during recursive scan to file.
--password secret
Use secret password to decrypt PDF files during batch processing.
--test-run [ fast ]
Only run batch processing in test mode to test PDF files or to obtain page count to estimate
total processing time. "fast" will only check the first page of each file, instead of going thru all
pages for image and vector analyzation.
--tag name
Use extended attribute name to tag the processing state of files during batch processing.
"macos:OCRKit (%s)" will use native macOS Finder tags instead, or simply "macos:OCRKit" not
including the state attribute. The order of the state attribute are:
"started", "analyzed", "processed", and can also be "encrypted"